
Why MultiAgentic Systems Still Struggle to Turn Data into Actionable Insights
What’s missing between data, agents and decisions

Preface
We keep adding agents.
We keep building smarter AI pipelines.
We keep shipping better dashboards.
And yet, SDRs still ask: “Who should I call next and why?”
Executives still ask: “What’s actually going wrong?”
Somewhere between AI-powered analytics & Agentic workflows, something breaks
A failure mode many teams are starting to recognise
But few have been able to articulate clearly..
It isn’t the models.
It isn’t the data.
It is CONTEXT.
Context resets at every step.
It gets fragmented across tools and
It gets summarised away just when decisions need it most.
Result: isn’t just bad analytics. It’s unusable outcomes. Reports arrive on time, dashboards look polished but neither helps an SDR choose their next move nor a leader commit to a decision.
Who Should Read This
AI and platform builders designing agentic systems that look correct but struggle to drive real decisions
Engineering and data leaders managing AI teams and wondering why well-designed pipelines still feel ineffective
Technical executives responsible for AI strategy who need to understand where decision-making actually breaks down
What You’ll Learn
Why correctness, modularity, and good prompts aren’t enough for decision-capable agentic systems
How context collapses across multi-agent pipelines and why dashboards are a symptom, not the problem
What decision traces are, and how letting them flow across agents creates global coherence
How to move from artifact-driven pipelines to context-continuous systems in practice
In this blog, we walk through a hands-on experiment that does two things:
Exposes why agentic AI systems fail to drive decisions
(Even when everything looks correct)Illustrates How letting Reasoning/Decision Context persist across an
SDR Analysis Pipeline turns analysis into real decisions.
Let’s DiveIn...
The Data–Business Gap Was Never a Tooling Problem
For nearly two decades, the technology industry has chased a deceptively simple goal: Become Data-Driven. Organizations modernised their stacks: first warehouses, then lakes, then cloud-native analytics platforms. Teams grew. Tooling matured. Metrics multiplied.
And yet, despite all this progress, a persistent gap remains between what businesses want to know and what data systems actually deliver.
The friction lies in the handoff. Business intent degrades as it moves through layers of abstraction as shown below:
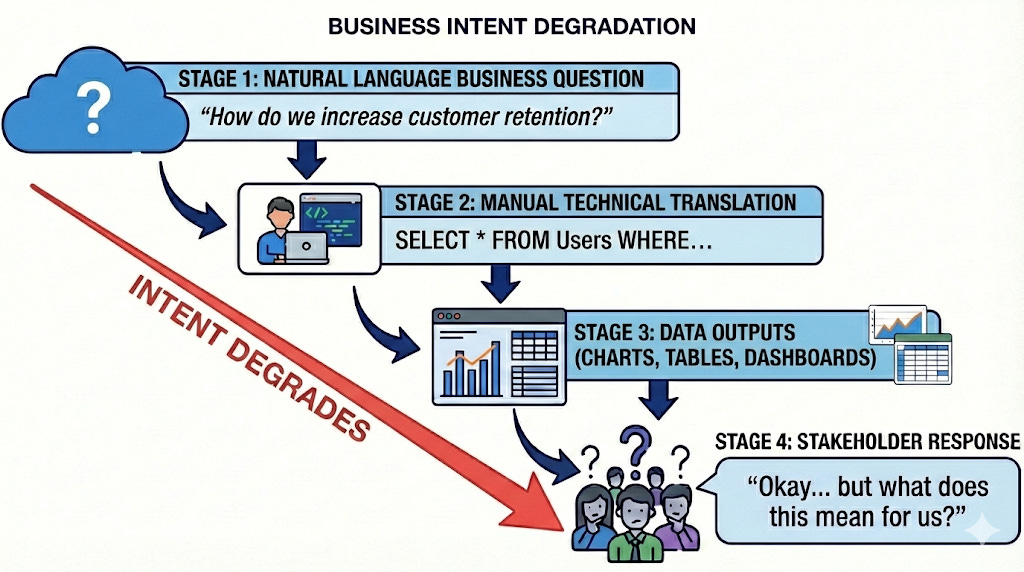
Reason: Modern BI systems were optimising for reporting correctness, not decision readiness.
First Wave of LLM Gains
Large Language Models (LLMs) have shown promise to fix this.
LLMs as Explaining Engines:
They introduced a way for Analysts to sanity-check their work by asking questions like:

If this went to an executive with limited time, would the core message be obvious?
Rewrite this summary to emphasise financial impact rather than technical nuance.
Is this visualisation answering a business concern or just showing activity?
This alone starts to compress the distance between analysis and understanding. But this was still a surface-level improvement.
Second Wave of LLM Gains
As LLMs improved, especially in their ability to handle longer contexts and structured reasoning, they began moving beyond explanation.
Second wave gains largely clustered around three improvements:
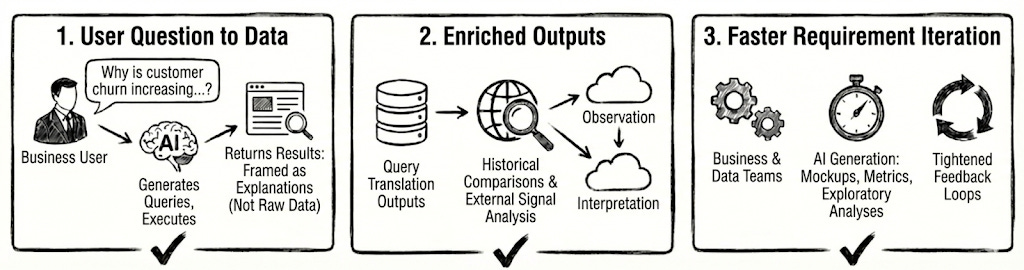
1. User’s Question to OutputData Translation
Business users can ask questions in plain language, while systems generate queries, execute them, and return results framed as explanations rather than raw data.
2. Enriching OutputData
AI can enrich outputs with historical comparisons, external signals, and lightweight recommendations thereby nudging conversations from observation to interpretation.
3. Faster Requirement Iteration
Mockups, metrics, and exploratory analyses can be generated rapidly, tightening feedback loops between business and data teams.
These gains materially improved speed and accessibility. Asking questions became easier. Iteration became faster. Insights arrived sooner. But even here, something fundamental remained missing.
Where these Wins Falls Short
Although these wins with AI are real improvements,
we are still optimising for reporting correctness, not decision readiness.
Reporting correctness answers “what is true”.
Decision readiness determines “what to do next”.
The Deeper Problem: How We Engineer Context
The requirements for decision readiness are fundamentally different. It depends on the system’s ability to:
Reconciling multiple data domains
Preserving intent across workflows and
Carrying context forward as understanding evolves.
Most AI systems are not designed to support these capabilities. This design gap is where things begin to break down, not because LLMs lack intelligence, but because of the way Agentic pipelines are engineered.
In most AI pipelines, what gets passed between steps are outputs, not context.
Charts, summaries, tables, and recommendations move forward, but the reasoning that produced them does not:
Why was this metric prioritised?
Which hypotheses were considered and discarded?
What assumptions still feel fragile?
What decision pressure shaped the analysis?
None of that travels with the output.
Without a way to carry this shared context forward, each step treats the previous one as finished work rather than ongoing reasoning. Understanding resets. Intent gets reinterpreted instead of refined.
The result isn’t a lack of insight, but a lack of momentum. Insights remain local, decisions stay fragmented, and organizations end up keep on going in loops asking smarter questions, faster, without getting any closer to action.
The Default Architecture Behind This Failure
The root cause is not the model. It is the way context is engineered into modern AI pipelines. The prevailing architecture pattern looks like this:
Each domain owns its own data models.
Each agent in the pipeline builds its own retrieval layer.
Crucially: Each agent works on a narrow slice of context, scoped to a single step.
From an engineering perspective: This feels modular and clean in a traditional functionality divide-and-conquer way
From a reasoning perspective: It is disastrous because Context becomes static and siloed i.e., fed into models at isolated points, then discarded. Agents cannot build upon each other’s understanding.
What emerges is a self-inflicted blindness
i.e., Systems that are locally smart, but globally incoherent.
A Practical Experiment: The SDR Analysis Pipeline
To make this concrete, an SDR-focused GTM (Go-To-Market) analysis pipeline was implemented. The goal was straightforward: identify why profitability was dropping in a specific region and help sales teams act on it. What we are seeking here is not reporting correctness but decision aiding feedback.
This experiment was conducted in two different ways. The roles were identical. The data was identical. The engineering of context was completely different.
Solution1: SDR Analysis Pipeline
Fragmented Context (Reason why it fails)
Solution1 was implemented as a standard, three-step pipeline where context was passed as artifacts (files/summaries) rather than reasoning state.
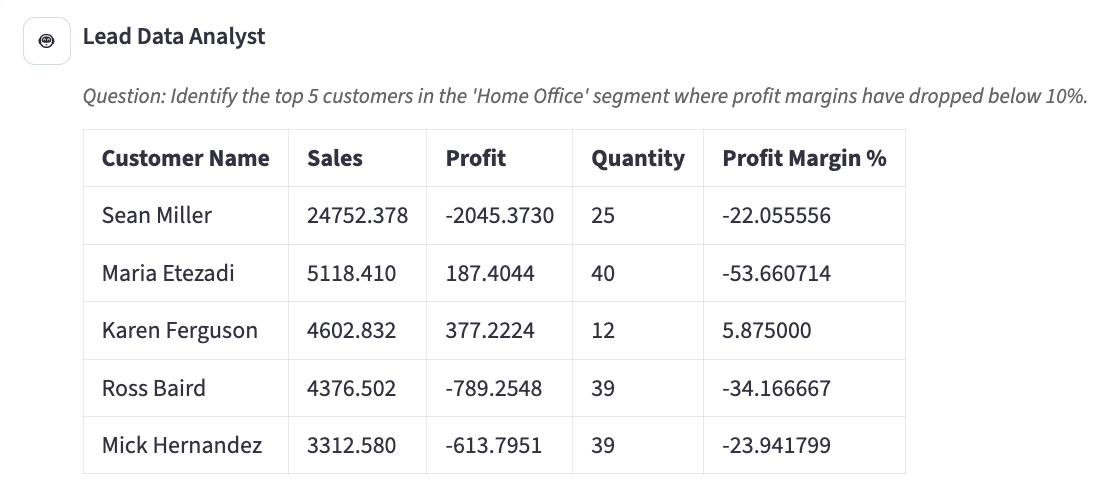
(Step1) Lead Data Analyst: Identified underperforming accounts.
(Step2) GTM Strategist: Wrote generic ROI narratives based on the data.
(Step3) Information Designer: Built a clean, standard executive dashboard.
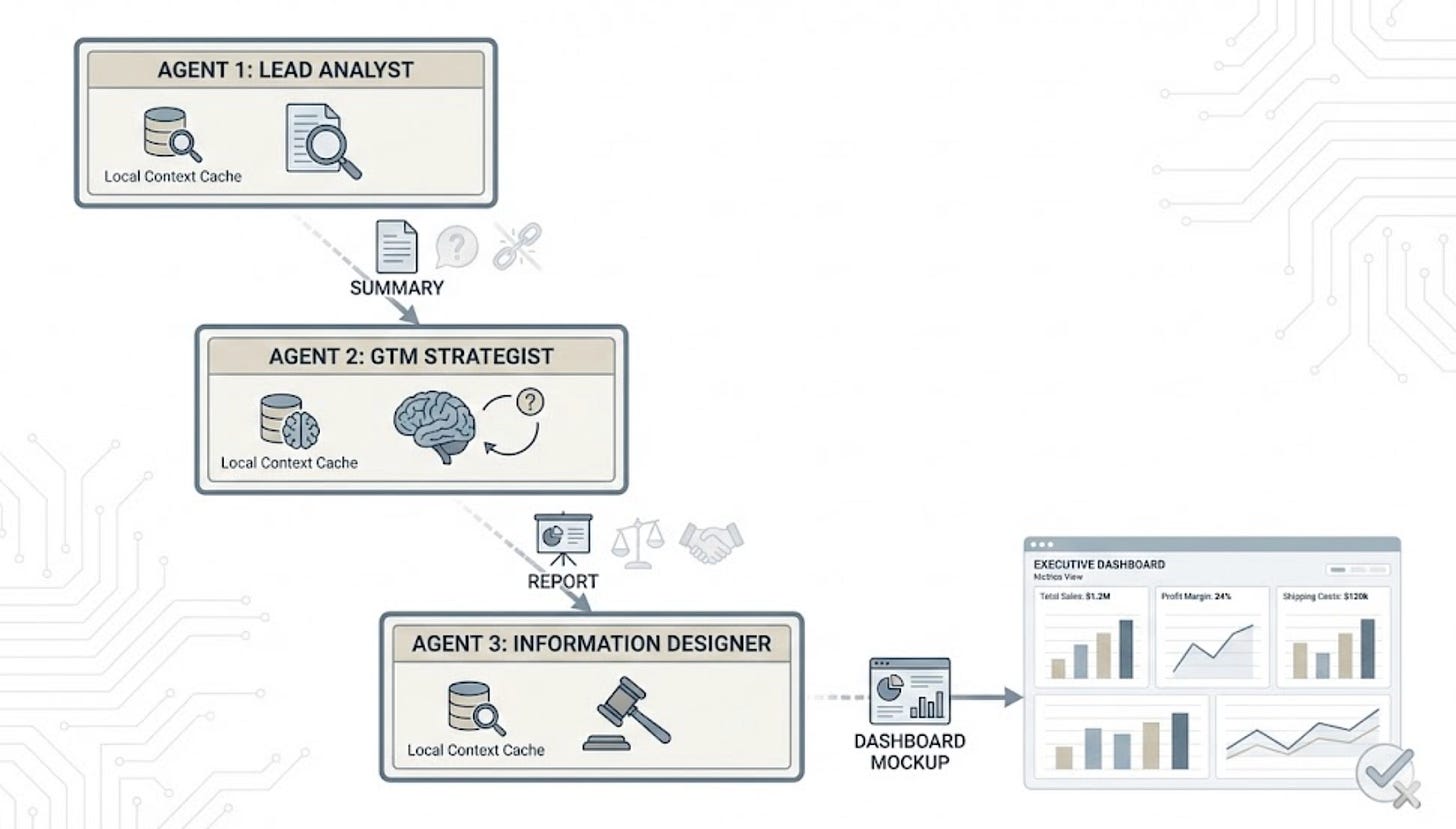
Solution1: AI Pipeline with three Agents that followed prevailing architecture pattern where one agent shared its output with the next. Ended up being locally-smart but global-incoherent.
Result:
Lead Data Analyst Agent surfaced the under performing accounts as shown below:
GTM Strategist Agent produced reasonable narratives for each account identified by Analyst agent:

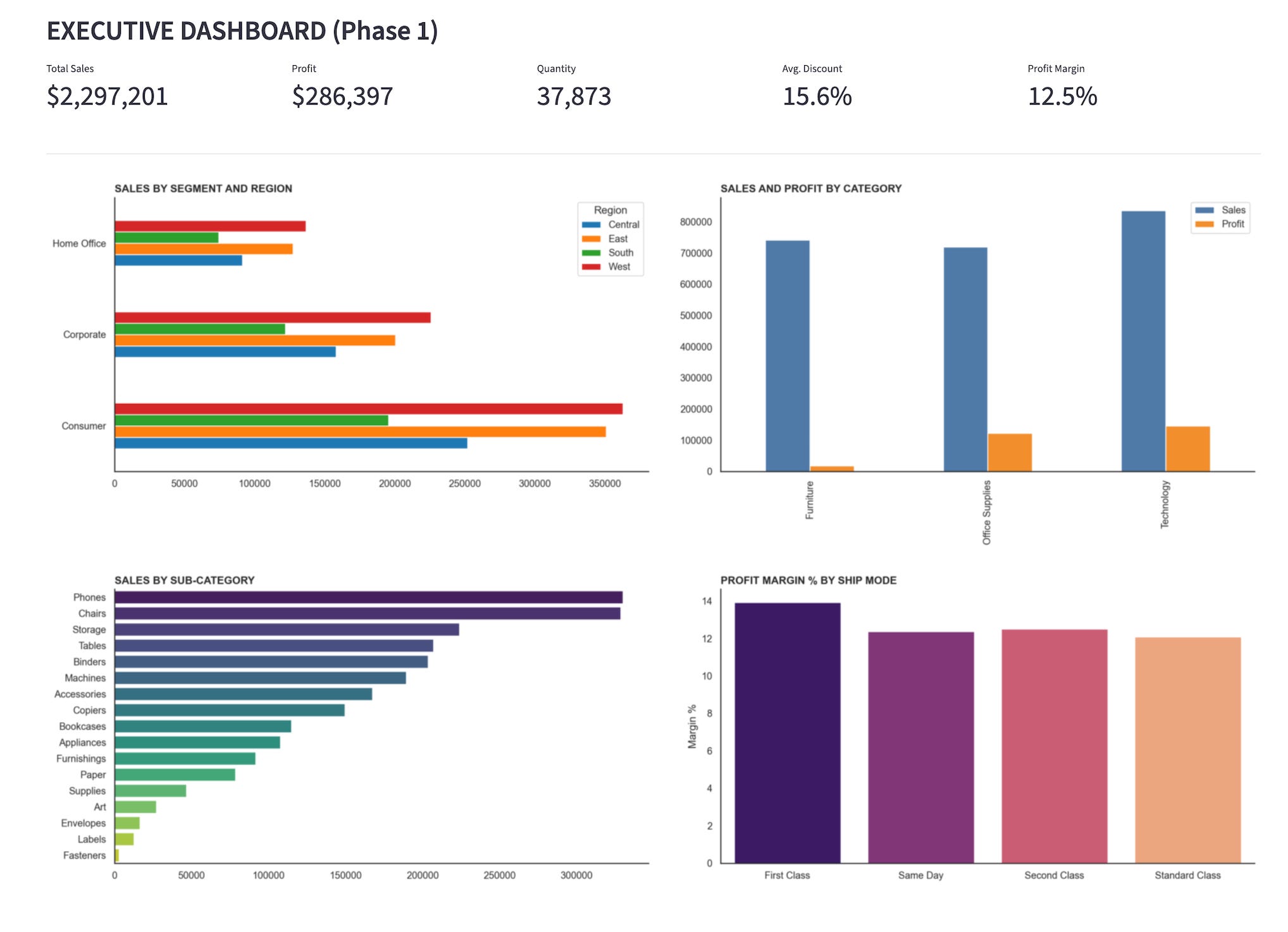
The Designer Agent delivered a polished dashboard.
Clearly, it looks polished and captured lot of insights but doesn’t align with the global story SDR is seeking. It ended up being fundamentally a generic dashboard that summarised activities without guiding action thereby loosing business purpose.
{kind=link}
What went wrong?
Result wasn’t ambiguous. Each agent was locally correct, yet, none of it added up to a decision. Here’s the reason why:
The Strategist Agent didn’t know why the Analyst picked those accounts.
The Designer Agent didn’t know which findings were critical versus exploratory.
The dashboard looked impressive, but it couldn’t tell an SDR what to do next.
This is the default locally-smart but global-incoherent failure mode
of most multi-agentic systems today.
This failure wasn’t a tooling issue.
It wasn’t a prompt issue.
It wasn’t even an agent design issue.
It is actually a Systems issue!!
Root Cause: Siloed Context
Solution1 illustrates what happens when decision-making reasoning is lost and
context becomes siloed. Agents end up being in a state where they cannot build on each other’s understanding.
The system can only summarise what happened in the past, but it cannot explain why it happened or what should happen next. Context collapses at every agent handoff. What emerges is a form of self-inflicted blindness and the system ends up becoming locally-smart and globally-incoherent.
Fix: You can’t reason about what you can’t observe.
In Solution1, the most important thing was never observable in the first place was the decision-making context itself.
The system had records for data, but no record of decisions.
Until that missing layer exists, adding more agents only magnifies incoherence.
That’s what Solution2 is going to addresses.
👉 Read Part 2 to see how :
Decision traces are preserved
Context flows across agents and
Agentic System becomes decision-capable along with a concrete implementation.
