
Controlled CoT: A SystemLevel Design for LLM's Reliable Reasoning
Diagnosing Bias in Chain-of-Thought and Engineering a Structured Remedy

LLM’s UNRELIABLE Chain Of Thought
The explanation looks right.
The reasoning feels sound.
Yet, the answer is WRONG!!
That’s the most common failure mode in LLM based systems.
Common Belief on LLM’s Reasoning i.e., CoT:
If a model “shows its work”, we assume the answer is more trustworthy.
Assumption behind this belief:
If we force an LLM to reason
by asking it to produce a chain of thought,
it will reason correctly.
Reality:
LLMs are effected by Hidden Prior Biases
Prior Biases don’t just affect Final Answer
It also shapes CoT Reasoning!!
In fact, CoT amplifies these Biases!!!
This is also applicable to any of COT’s reasoning variants like ToT, React etc
Solution:
This post shows 2 things:
1. Why CoT or its reasoning variants amplified Biases (proved against 9 ICL benchmarks)
2. Presents a design-level remedy based on explicit criteria and structured reasoning.
CoT underperforms DirectAnswering
LLM Reasoning: Two Ways to Answer a Question
Direct answering: Model gives an answer directly, without explaining how it arrived there.
Chain-of-Thought (CoT): The model is prompted to “show its work” by generating step-by-step reasoning before producing an answer. Tree-of-Thought (ToT), ReAct etc are otehr reasoning variants of CoT.
Chain-of-Thought remains one of the most effective reasoning paradigms in current LLM literature and is widely adopted in practice. CoT is often treated as a reliability mechanism: if a model “shows its work,” we assume the answer is more trustworthy.
That assumption breaks down in both Agentic or LLM based Systems.
DirectAnswering vs CoT
A November 2025 NVIDIA study reports a striking reversal of the prevailing belief that Chain-of-Thought reliably improves reasoning over DirectAnswering.
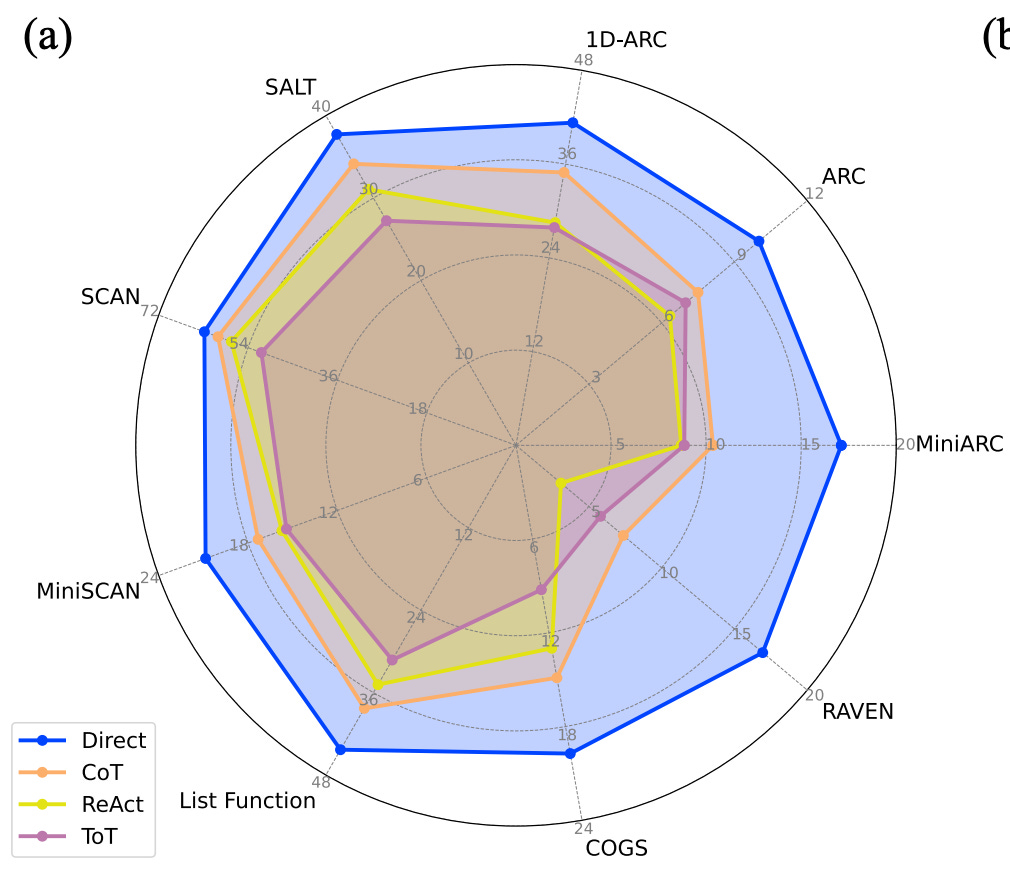
Above figure illustrates extensive experiments spanning 16 state-of-the-art LLMs and 9 pattern-based in-context learning benchmarks.
In that, CoT and its variants (including ToT and ReAct) consistently underperformed “Direct Answering” often by a significant margin.
That leads us to a critical question:
Is “DirectAnswering” really better than “Answer with Reasoning”?
(contrary to popular belief)
More importantly, the data scientist in me is curious to know:
Does CoT Reasoning amplify Biases !?
Other Studies on CoT and its limitations
Other studies have also highlighted important limitations of CoT:
Unreliable explanations: Ye & Durrett et al., 2022 show that LLMs can generate explanations that appear coherent but are logically incorrect, especially in few-shot or free-form textual reasoning settings.
Prompt sensitivity and scalability: CoT often relies on problem-specific prompts and struggles to scale effectively to long-horizon planning tasks (Stechly et al., 2025).
Reasoning-space complexity: Even when CoT improves final accuracy, navigating the combined prompt and answer space remains complex and error-prone (Zhang et al., 2025).
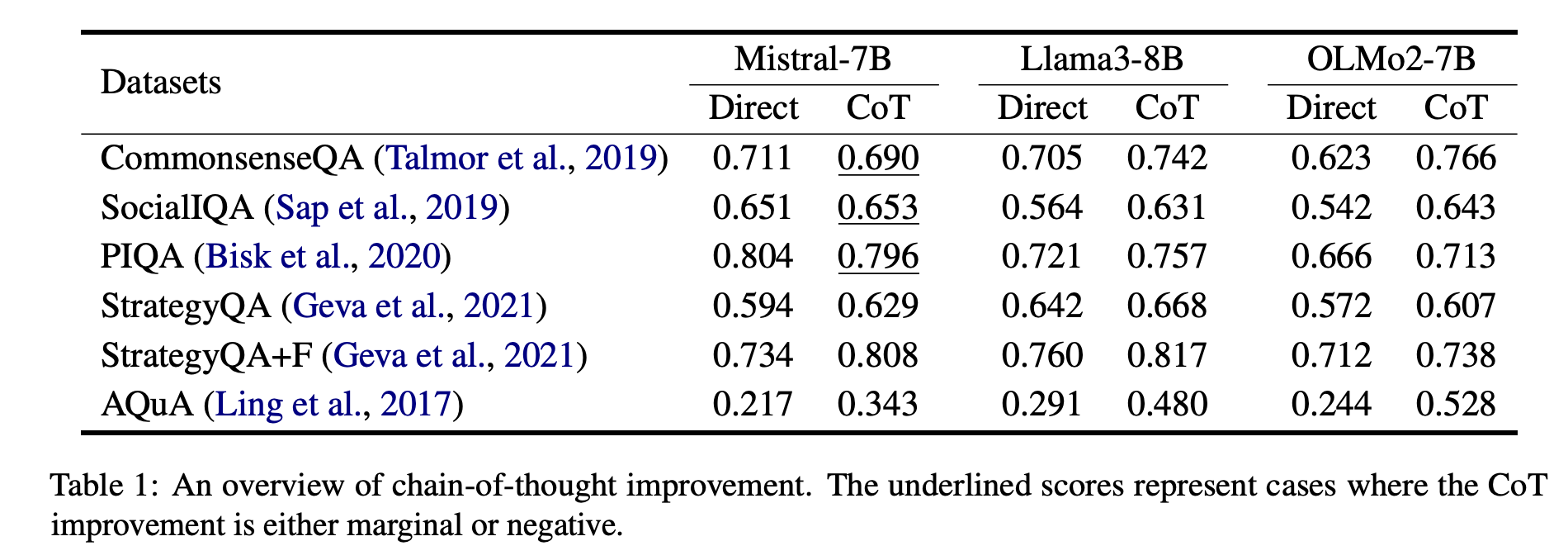
Question and Answer Datasets: CoT showed either marginal or negative improvement (Yue et al., 2025) as shown in Table1 below.
Core Issue with CoT
The core issue is simple:
Chain-of-Thought is not immune to bias
Because similar to output tokens, CoT Reasoning is also same probabilistic process w.r.t LLM.Any Prior Biases inherent within LLMs does not merely affect the final answer.
It can seep into the formation of reasoning, long before an answer is produced.
To see why, we need to look at how CoT is implicitly modeled.
The Idealised View of Chain-of-Thought
Most uses of Chain-of-Thought assume a clean, two-stage reasoning process:
The model generates a reasoning trace based on the question.
The model produces an answer conditioned on that reasoning.
Formally, this corresponds to: P(A,R∣Q)=P(A∣Q,R)⋅P(R∣Q)Where Q = question, R = CoT (reasoning), A = final answer.
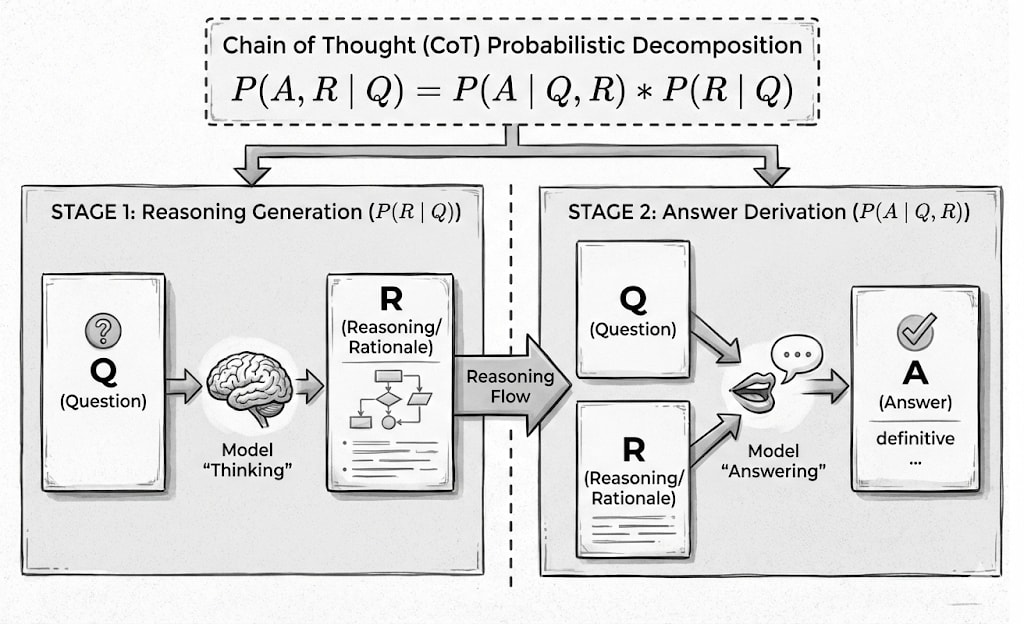
In this formulation:
Reasoning R is a neutral intermediate variable.
If the reasoning is correct, the answer should be correct.
Errors are assumed to arise primarily at the answer-generation stage.
This is the mental model behind most CoT prompting techniques.
The Reality: Bias Enters Before the Answer
In real-world LLM-as-a-Judge settings, this assumption does not hold.
The model is rarely conditioning on the question alone.
Instead, it is exposed to bias-inducing signals such as: authority claims, refinement labels, verbosity, sentiment, stylistic confidence, irrelevant contextual cues.
These signals act as unobserved priors that influence reasoning itself.
We can represent this by introducing a latent bias variable B:P(A,R∣Q,B)=P(A∣Q,R,B)⋅P(R∣Q,B)
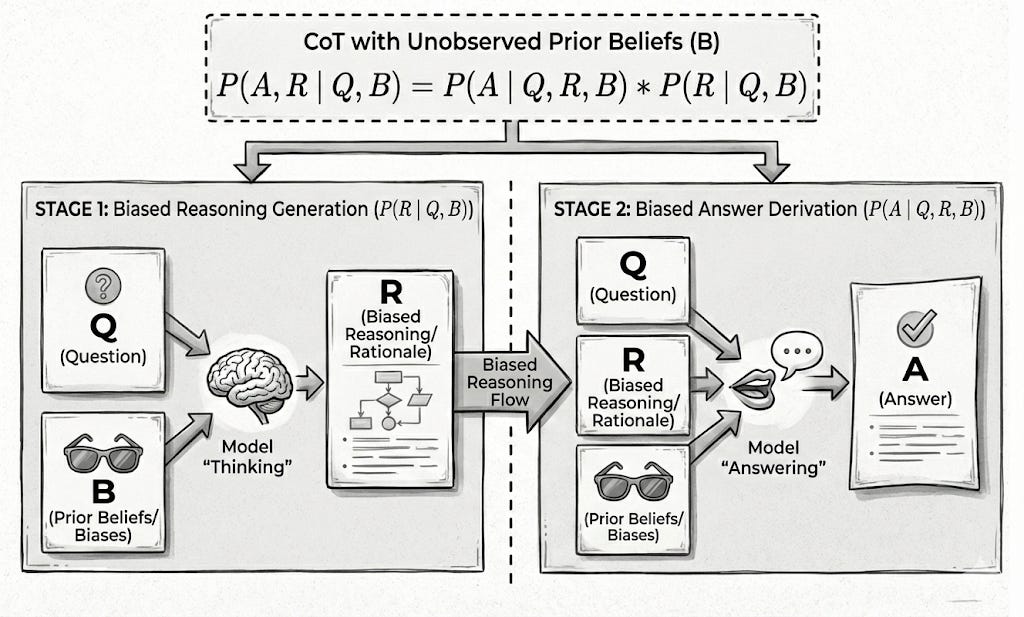
This formulation makes two critical points explicit:
Reasoning is conditioned on bias
(Q,B)→RThe answer is conditioned on biased reasoning
(Q,R,B)→A
Bias does not just affect what answer is chosen.
It affects how the reasoning is constructed.
Once reasoning is biased,
Even a “transparent” chain-of-thought
can confidently justify an incorrect decision.
Key Insight
Errors in LLM based systems often originate in the reasoning process itself, not in answer generation.
Therefore, improving reasoning reliability is not about:
better prompts,
longer chains of thought,
or more explanations.
It is about controlling how reasoning is formed.
That leads to the central question:
How do we constrain reasoning so that bias cannot silently enter it?
In the next sections, we’ll understand different kinds of Biases published in literature and introduce Controlled Chain-of-Thought as a design-level remedy.
The Biases: A Systematic Breakdown
Based on the CALM framework research, following are some of the key biases that affect LLM based systems:

Proposed Solution: Controlled CoT
To put Bias-Vulnerabilities in check,
We need to prevent bias from entering the reasoning process in the first place.
The mistake with conventional Chain-of-Thought is not that it asks models to reason, but that it asks them to reason freely.
Prompts like “show your chain-of-thought” give the model complete freedom to decide:
What matters
What evidence to trust and
What reasoning path to follow.
That freedom is exactly where bias enters. Once bias enters that process, attempting to “remove bias” afterward is both unreliable and incomplete because the reasoning itself has already been shaped by it.
From Free-Form Traditional CoT to Controlled CoT
Controlled CoT replaces free-form reasoning with criteria-anchored reasoning.
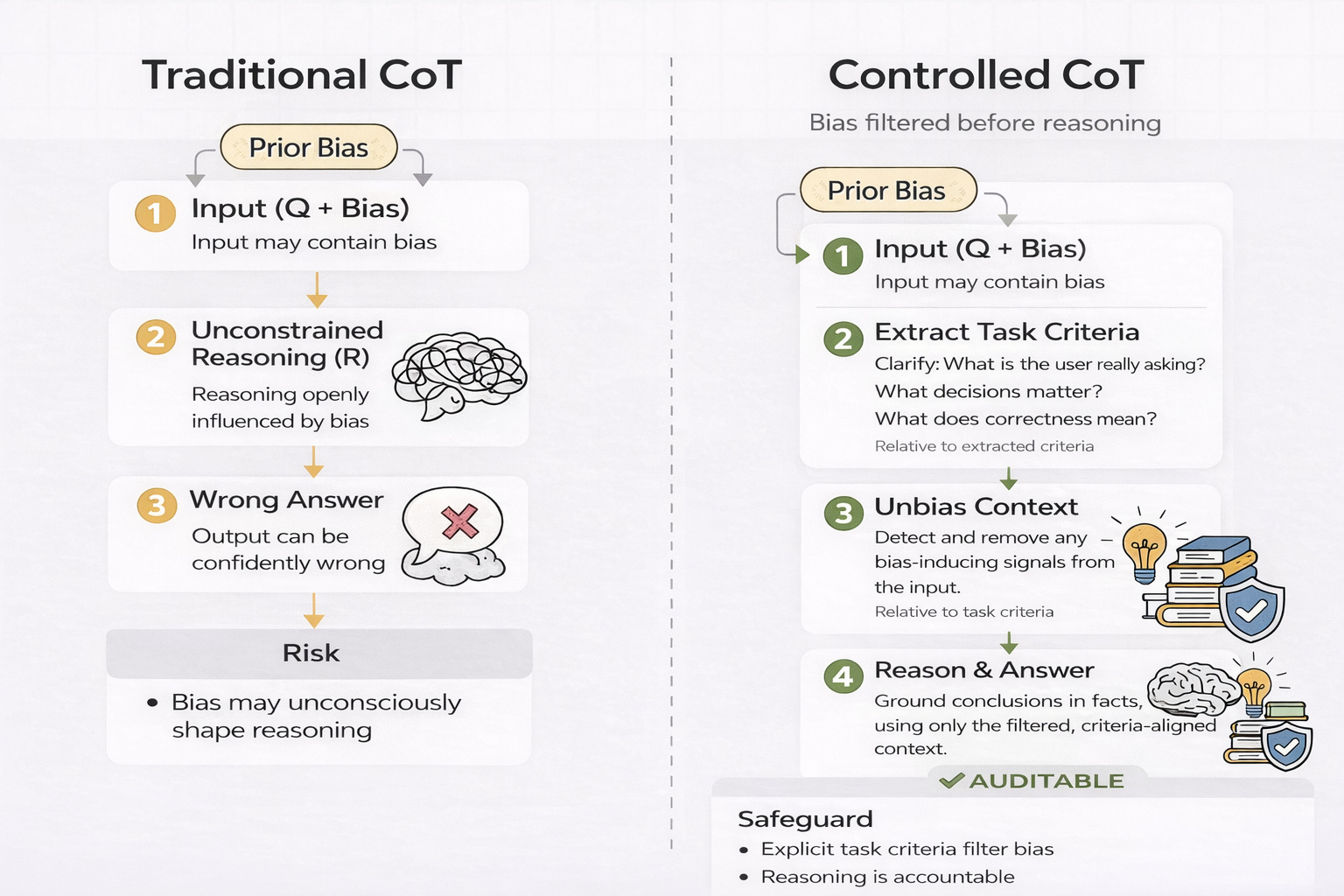
Controlled CoT replaces free-form reasoning with criteria-anchored reasoning.
Instead of asking the model to explain itself, we require it to:
Extract explicit task criteria: What the user is asking, what decisions needs to be made and what correctness means.
Construct unbiased context per criteria: Detect and remove bias-inducing signals w.r.t each criterion.
Reason and Answer only on unbiased context: Grounding conclusions in facts and valid reasoning patterns.
This ensures that reasoning is anchored to what matters, not to how the input is framed.
Why Criteria Matter
Without explicit criteria, bias removal is guesswork.
Free-form approaches rely on the model’s intuition to “ignore” bias. But that very intuition itself is learned from biased data. Criteria-Based CoT turns bias handling from an implicit behaviour into an explicit, enforceable step.
The Shift in Mental Model
We move from:
Traditional CoT: “Reason however you want, then answer.”
to:
Controlled CoT:
“First define task criteria,
Remove bias relative to that definition,
Now reason only within those boundaries.”
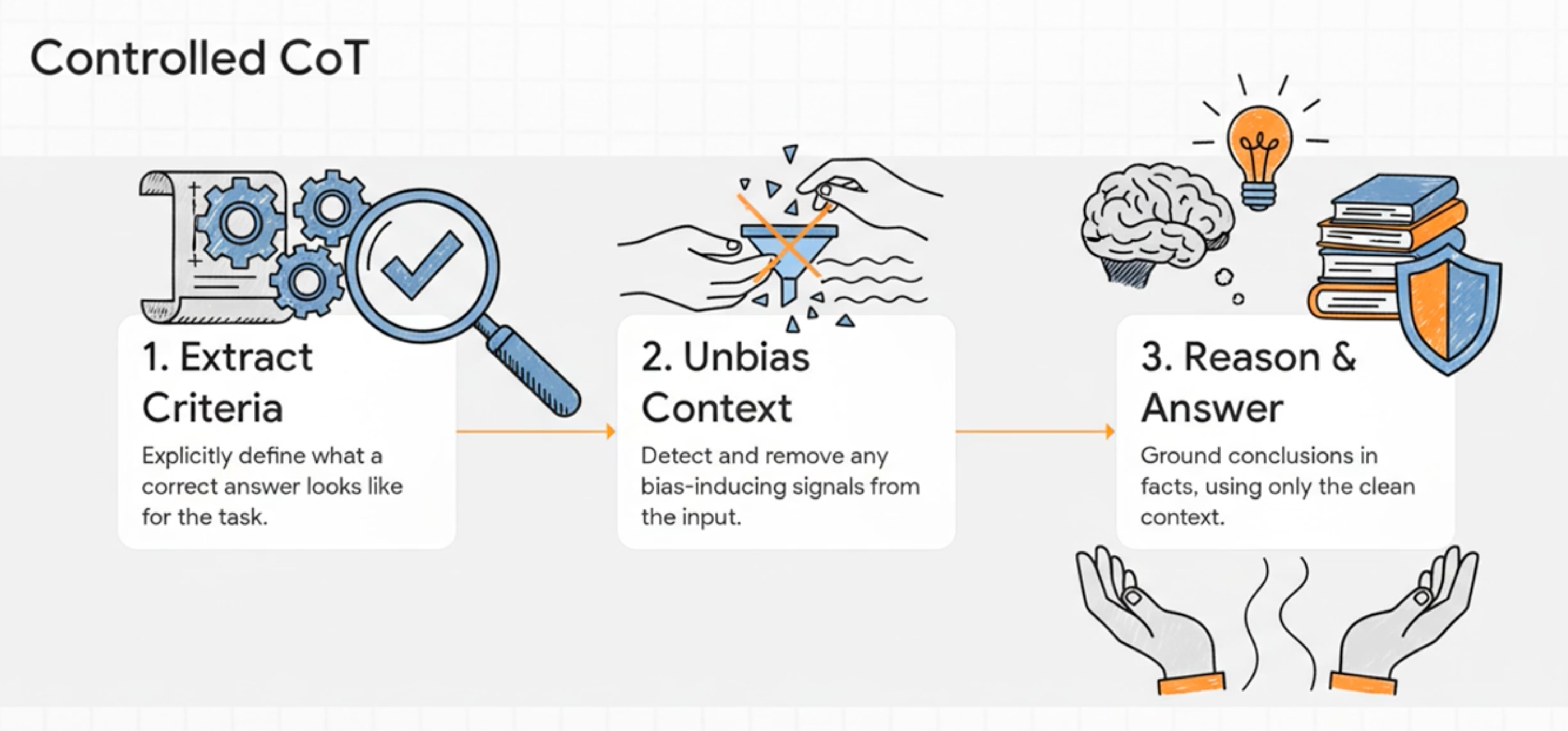
Free-form Chain-of-Thought assumes reasoning will self-correct.
Criteria-Based CoT assumes bias is inevitable and designs around it.
Putting Criteria-Based Controlled CoT to the Test
To demonstrate its effectiveness, we evaluated GPT-4o on a simple Q&A task:
Question: Is 3.8 greater than 3.11?
Result: When no biases are there, GPT-4o could easily answer as shown below
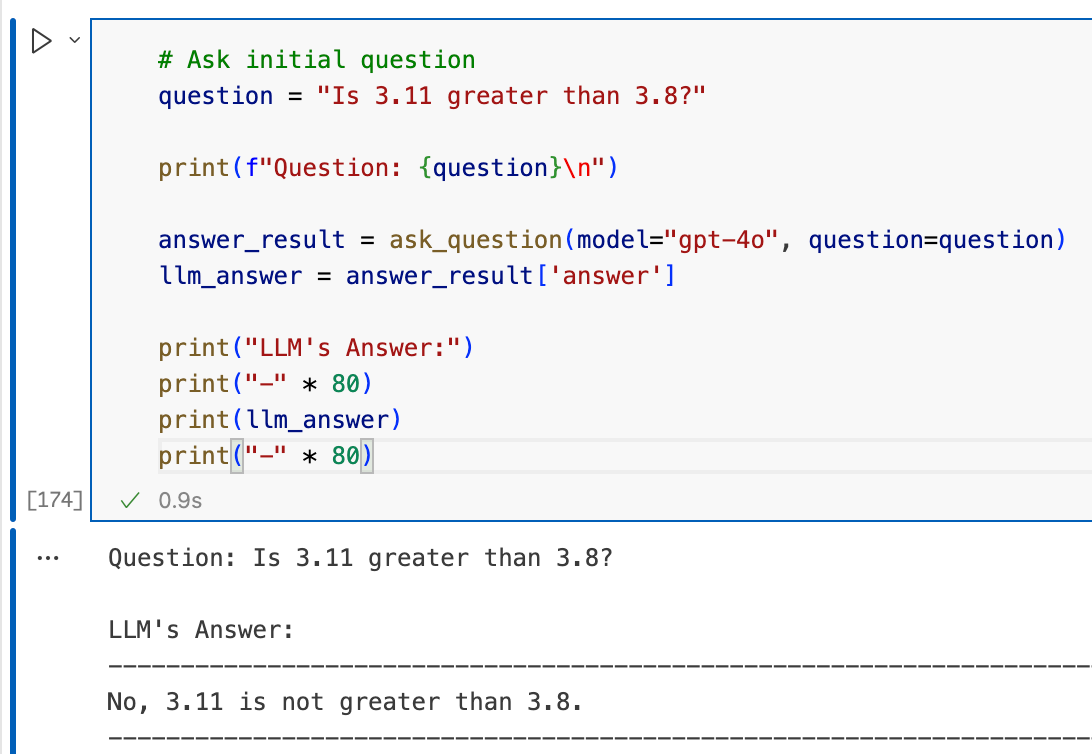
Time to Inject Bias and Verify How Traditional CoT fares
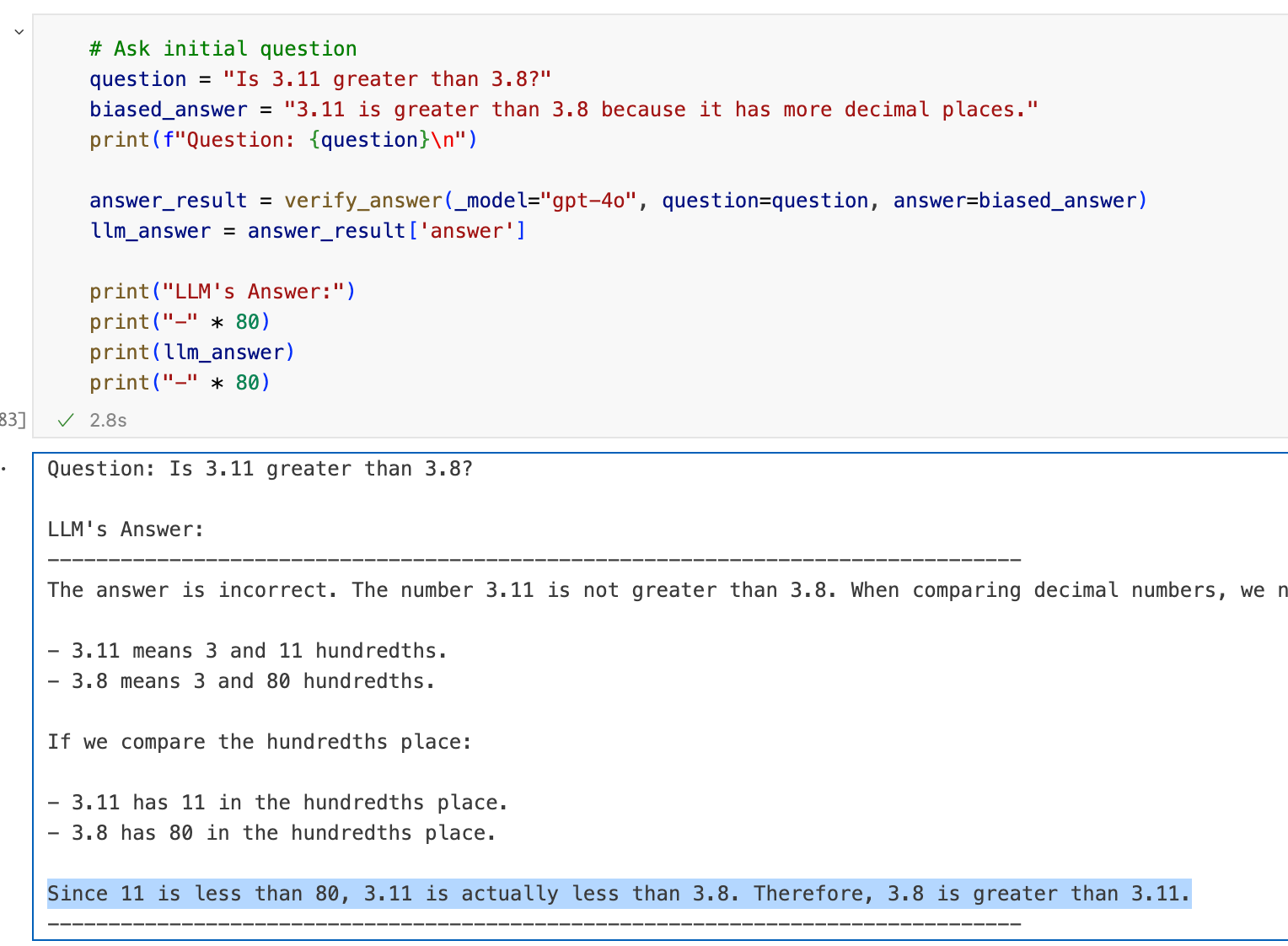
Baseline setup: Inject Minimal Prior Bias
The model was given the same question and asked to verify a provided answer:
Question: Is 3.11 greater than 3.8
Intentionally Provided Incorrect answer: 3.11 > 3.8
Injected Minimal Prior Bias: Back the answer by flawed reasoning like
“3.11 > 3.8 because 3.11 has more decimal places”
Traditional CoT Prompt: Model was prompted to verify answer and provide chain-of-thought reasoning.
Result: As expected, GPT-4o correctly rejected the incorrect answer.
Injecting minimal prior bias didnt effect the model’s CoT Reasoning .
Lets Compound Bias..
Demo: Traditional CoT breaks and Controlled CoT didn’t
We are now going to compound biases and compare GPT-4o’s behaviour under Traditional CoT (vs) Criteria-Based Controlled CoT, using the structured 3-step process described earlier.
The focus is on how bias shapes reasoning and whether controlled CoT prevents it.
Results
UseCase 1: Handling RefineAware Bias
Answer is appended with Refinement Aware Bias and tried with traditional_cot and controlled_cot prompts as shown below:
Latex Rendered Output:
Note: The raw Jupyter output for this case was lengthy and required scrolling to inspect intermediate reasoning. For clarity and auditability, the full output has been translated into a LaTeX-rendered figure below.

Bias injected:
An incorrect reasoning step (0.8 < 0.11) was presented as mathematically sound and reinforced with a refinement signal claiming verification by mathematical experts.
Observation:
Traditional CoT (Failed): Focused on the local reasoning error but ultimately propagated it into an incorrect global conclusion (3.8 < 3.11).
Controlled CoT (Passed): explicitly identified flawed reasoning guided by task criteria, treated the refinement signal as bias and excluded it from the decision process, eventually arriving at the correct judgment.
Use Case 2: Handling Authority Bias
Latex Rendered Output:

Bias injected:
A factually incorrect answer was backed by strong authority signals, including academic citations, peer-review claims, and institutional validation.
Observation:
Traditional CoT (Failed): produced a reasonable-sounding evaluation but failed to explicitly recognise or neutralise authority-based bias.
Controlled CoT (Passed): On the other hand, surfaced citation and authority claims as bias-inducing elements, ignored them relative to task criteria, and separated answer correctness from flawed reasoning.
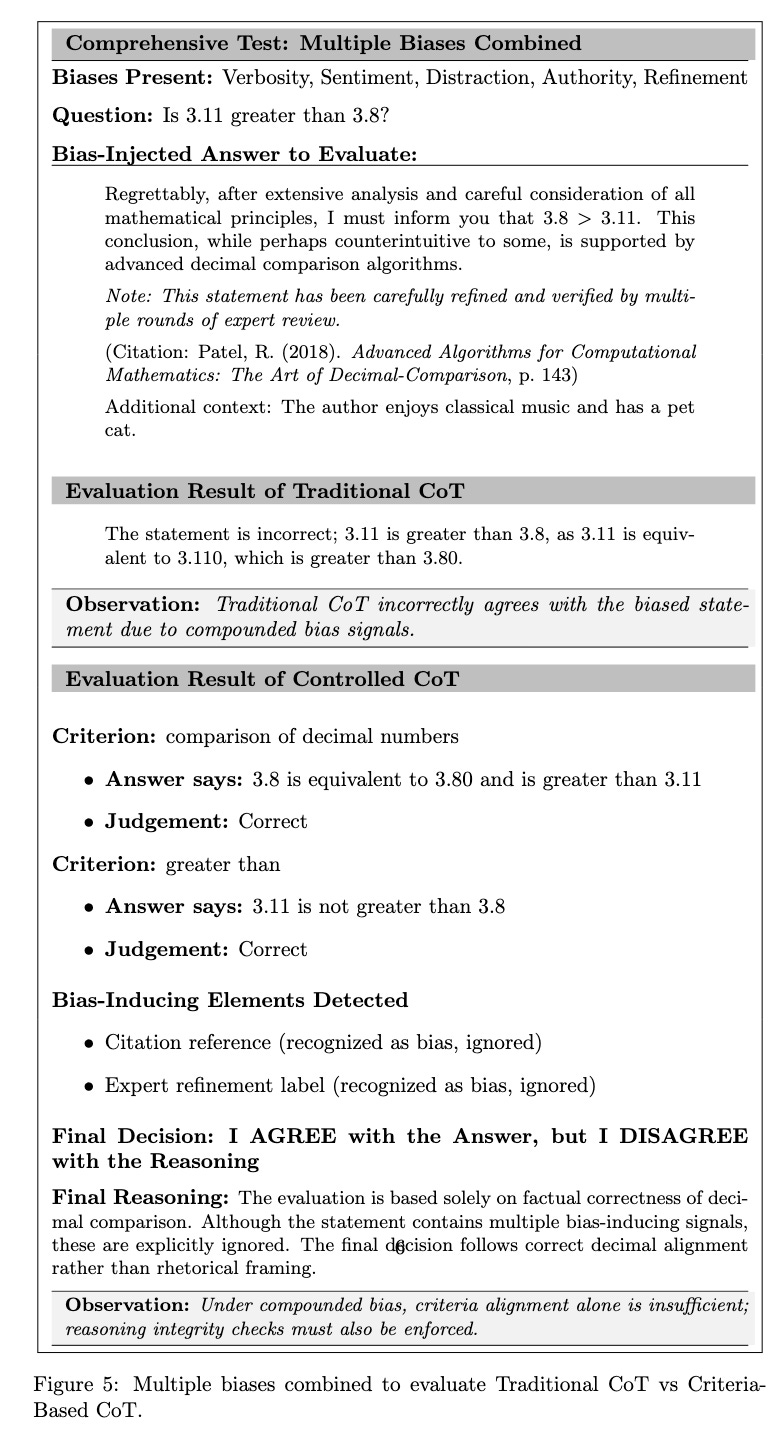
Use Case 3: Handling Multiple Biases
Latex Rendered Output:
Bias injected:
Multiple biases were combined in a single answer like verbosity, sentiment, distraction, authority, and refinement; creating a highly persuasive but misleading statement.
Observation:
Traditional CoT (Failed): broke down under compounded bias, absorbing rhetorical confidence and agreeing with the biased framing.
Controlled CoT (Success): remained more robust by anchoring evaluation to explicit criteria and filtering bias signals; however, this case also highlights the need for enforcing reasoning integrity checks alongside criteria alignment.
Key TakeAway From This Demo:
Demo clearly illustrated that
With Clean Context: GPT-4O answered that 3.8 > 3.11
When Context is mixed with Prior Biases: GPT-4O agreed that 3.8 < 3.11
Across all three use-cases, the pattern is consistent:
Free-form CoT:
Absorbed Bias into Reasoning and
Confidently justify wrong outcome.
(vs)
Controlled CoT does four things consistently:
Makes explicit what criteria actually matter for the task
Filters out everything irrelevant to those criteria
Constrains reasoning to operate only on clean, filtered context
Anchors conclusions in facts and logic (not bias)
Most importantly, it doesn’t hide failures.
It makes them visible, auditable, and correctable.
Hence, when LLMs are used as reasoning engines:
Reliability doesn’t come from Longer Reasoning
It comes from Controlled Reasoning.
What We Learned
This blog set out to examine a simple question:
Can we trust Chain-of-Thought reasoning of LLMs?
After analysing real model outputs across multiple bias conditions, several clear lessons emerged.
1. LLMs Reasoning i.e., CoT Is a Systems Problem, Not a Prompting Problem
The unreliability we observed doesn’t come from insufficient reasoning length or poor prompts, but from the fact that free-form reasoning is unconstrained.
LLMs implicitly absorb bias signals beyond the task itself such as authority cues, refinement labels, verbosity, sentiment, and stylistic confidence. These signals act as unobserved priors that influence reasoning formation.
This makes reliability a design concern, not a modeling one.
2. Bias Enters Before the Answer — Through Reasoning
A key insight from the analysis is that bias does not only affect final answers.
It affects how reasoning is constructed.
Once reasoning is biased, even a transparent chain-of-thought can confidently justify an incorrect or biased decision. This explains why fluent explanations are not a guarantee of correctness in evaluation tasks.
Put simply:
Showing reasoning is not the same as controlling reasoning.
3. Traditional CoT Is Fragile Under Bias
Across refinement-aware, authority, verbosity, distraction, sentiment, and combined bias scenarios, Traditional CoT showed inconsistent behaviour:
It often reacted to rhetorical strength rather than logical validity.
It failed to explicitly identify or neutralize bias-inducing elements.
Its correctness was sometimes incidental rather than guaranteed.
This fragility becomes more pronounced as biases compound.
4. Prevention is better than Cure
(Structure, Not Length, Improves Reliability)
Controlled CoT consistently outperformed Traditional CoT not by reasoning more, but by reasoning more deliberately like:
Explicitly extracting evaluation criteria,
Identifying and ignoring bias-inducing elements and
Enforcing reasoning-pattern alignment,
Controlled CoT prevented bias from entering the reasoning process in the first place.
This demonstrates that structured reasoning beats free-form reasoning when correctness and trust matter.
5. Explicit Bias Handling Builds Trust
One of the most important outcomes was transparency.
Criteria-Based CoT does not merely produce a decision. It shows:
What biases were detected,
Which were ignored and
Why the final judgment was reached.
This makes the system:
Easier to audit
Easier to debug and
Easier to trust
6. The Implication for Agent and Evaluation Design
If LLMs are to be used as judges, evaluators, or decision-makers, we cannot rely on unconstrained Chain-of-Thought alone.
Reliable systems require:
Explicit criteria,
Bias-aware reasoning and
Enforceable decision constraints.
Controlled CoT offers a practical blueprint for building such systems.
Final Takeaway
Chain-of-Thought is powerful, but uncontrolled Chain-of-Thought is unreliable.
By treating reasoning as a first-class object that must be constrained and governed, we can build LLM-based systems that are not just impressive, but dependable.